TL;DR
ContextTracker erfasst Arbeitszeiten automatisch, indem es Browser-Aktivitäten und Dateiänderungen beobachtet und im Nachhinein kundenbezogen zusammenführt. In Woche 2 habe ich das Backend und eine erste Version des Frontends umgesetzt; die Browser-Extension und der Hintergrund-Worker folgen als Nächstes. Der Kernnutzen: Zeiten fallen ohne manuelles Start/Stop an, werden logisch zu Sessions gebündelt und Kunden zugeordnet. Das lokale Setup lief dank SSH‑Tunnel stabil, und die gründliche Planung aus Woche 1 hat die Entwicklung mit dem LLM deutlich beschleunigt. Fazit: Die Basis steht, als nächstes geht es an die kontinuierliche Datenerfassung.
Kontext & Ziel
Viele Freelancer arbeiten parallel für mehrere Kunden und wechseln im Tagesverlauf oft zwischen Tabs, Tools und Dateien. Dabei gehen schnell Minuten verloren, weil ein Timer nicht gestartet wurde oder weil die Erfassung zu grob ist. ContextTracker setzt genau hier an: Statt manueller Stoppuhren beobachtet das System den Kontext, in dem du arbeitest, und rekonstruiert daraus deine Sessions. Ziel für Woche 2 war ein lauffähiges Backend mit Datenmodell, APIs für Events, Kunden und Aufbereitung sowie ein Frontend, das die wichtigsten Flows abbildet. Dabei bin ich von der ursprünglichen Planung abgewichen: statt der Browser-Extension und des Workers habe ich das Frotnend vorgezogen. Offen sind jetzt also noch die Browser‑Extension und der lokale Worker, die die Rohdaten kontinuierlich liefern.
Meine Anforderungen
- Ich möchte Zeiten automatisch erfassen, ohne an Start/Stop denken zu müssen
- Ich brauche eine klare Zuordnung zu Kunden, basierend auf besuchten URLs und bearbeiteten Projektpfaden
- Ich will nachträglich verstehen, wie viel Zeit pro Kunde und Aktivität angefallen ist
- Ich möchte Sessions logisch zusammengefasst sehen, statt 100 einzelner Klick-Events
- Ich will Daten in einer Datenbank speichern und später einfach auswerten können
- Ich brauche eine einfache Oberfläche für Kunden, Regeln und Einstellungen
- Ich will lokal entwickeln und testen können, ohne die Produktivumgebung zu berühren
Mein AI-Workflow
Ich habe mit Claude Code entwickelt und die Planung aus Woche 1 als Leitplanke genutzt. Dank der ausführlichen Planung war das Promopten diese Woche super simpel! Das hat mir sehr gefallen! Backend UND Frontend liefen beide sehr schnell, die meiste Zeit ging also diese Woche in den SSH-Tunnel und an das Anpassen des Designs.
Für das Titelbild nutze ich weiterhin ChatGPT. Da habe ich diese Woche sogar den gleichen Chat verwendet, da der Kontext zum Projekt ja der gleiche ist.
Was das Tool können wird
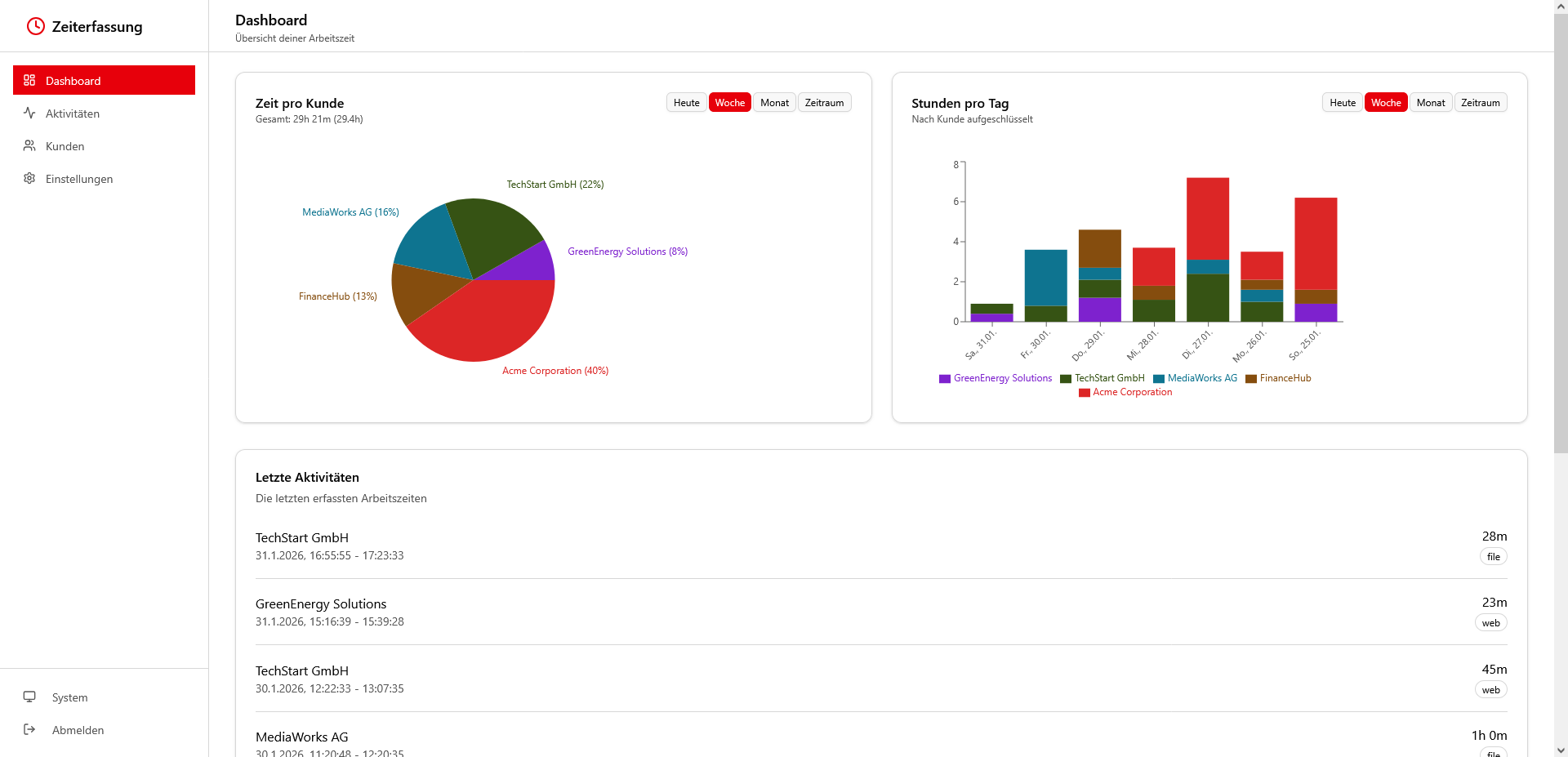
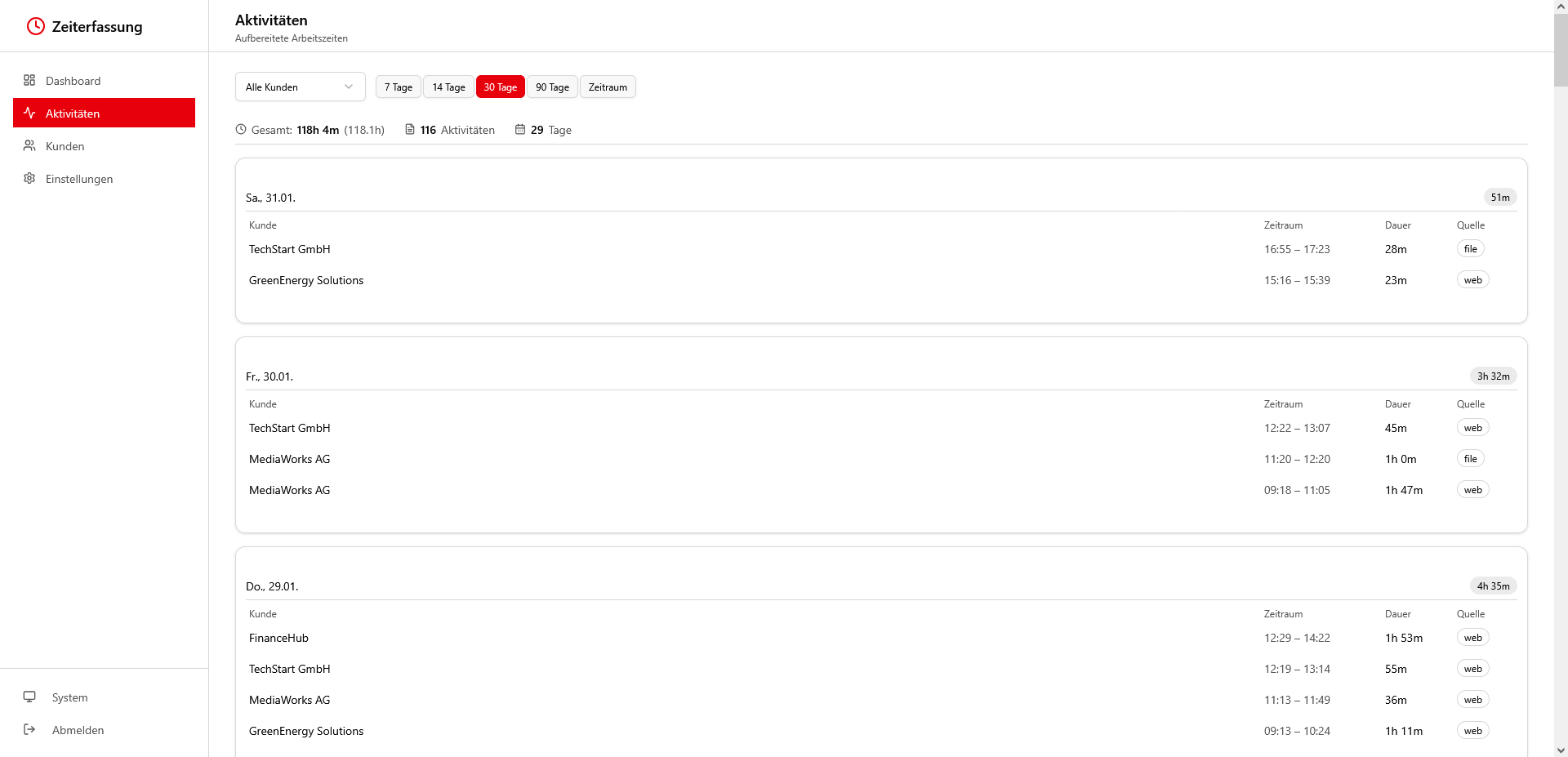
👉 Du hinterlässt beim Arbeiten Spuren: besuchte Webseiten und geänderte Dateien. ContextTracker nimmt diese Ereignisse entgegen, speichert sie strukturiert und wandelt sie in Sessions um, die verständlich deinem Arbeitstag zugeordnet sind
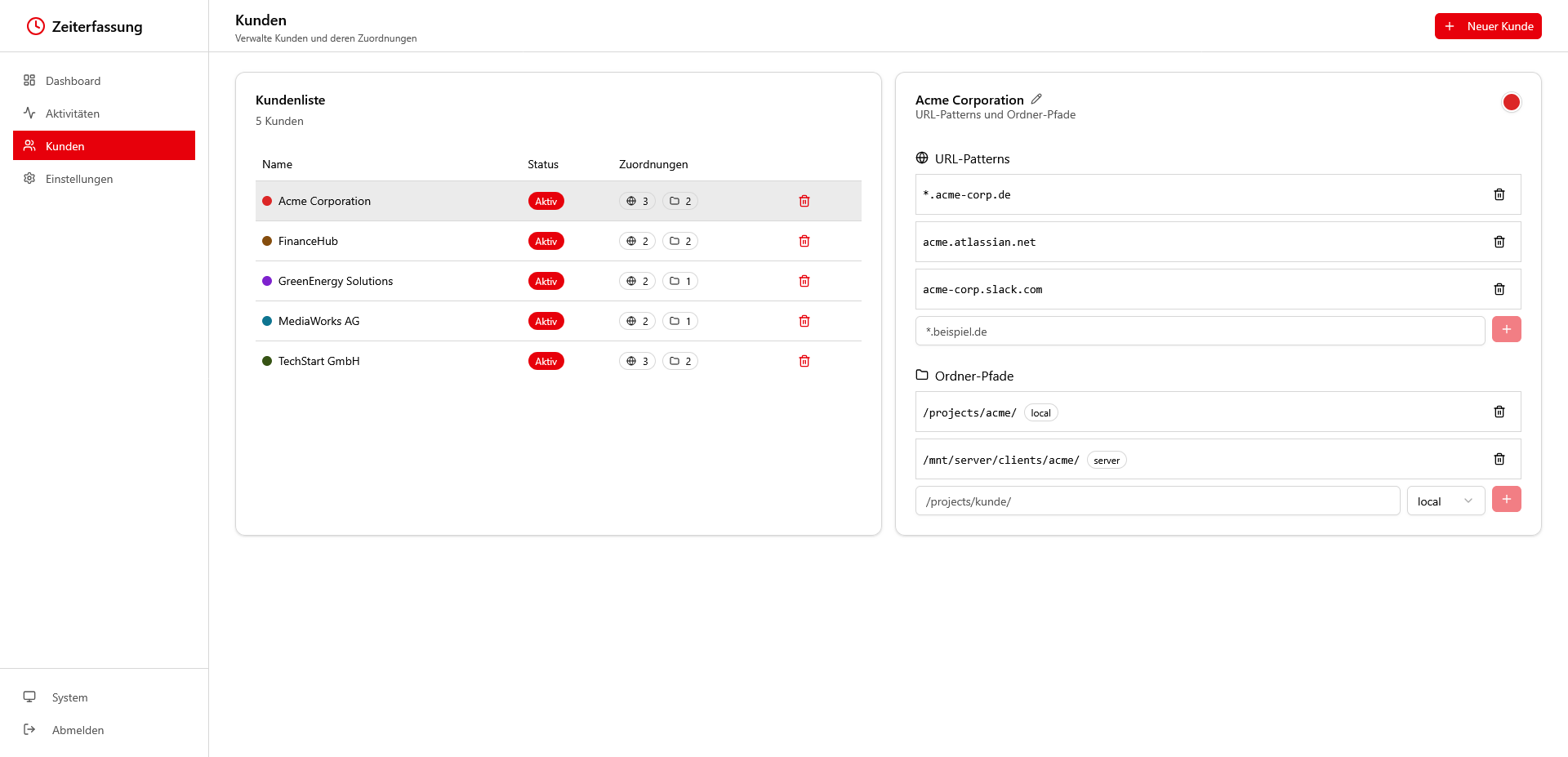
👉 Kunden werden über URL‑Muster und Projektpfade erkannt. Ein Eintrag wie acme.atlassian.net oder ein lokaler Ordnerpfad reicht, um Aktivitäten später eindeutig zuzuordnen ✅
👉 Im Dashboard siehst du Tages‑ und Wochenansichten mit kumulierten Zeiten je Kunde.
👉 In der Kundenverwaltung pflegst du Namen, Status und Erkennungsregeln. So lässt sich ein neuer Kunde in Minuten anlegen
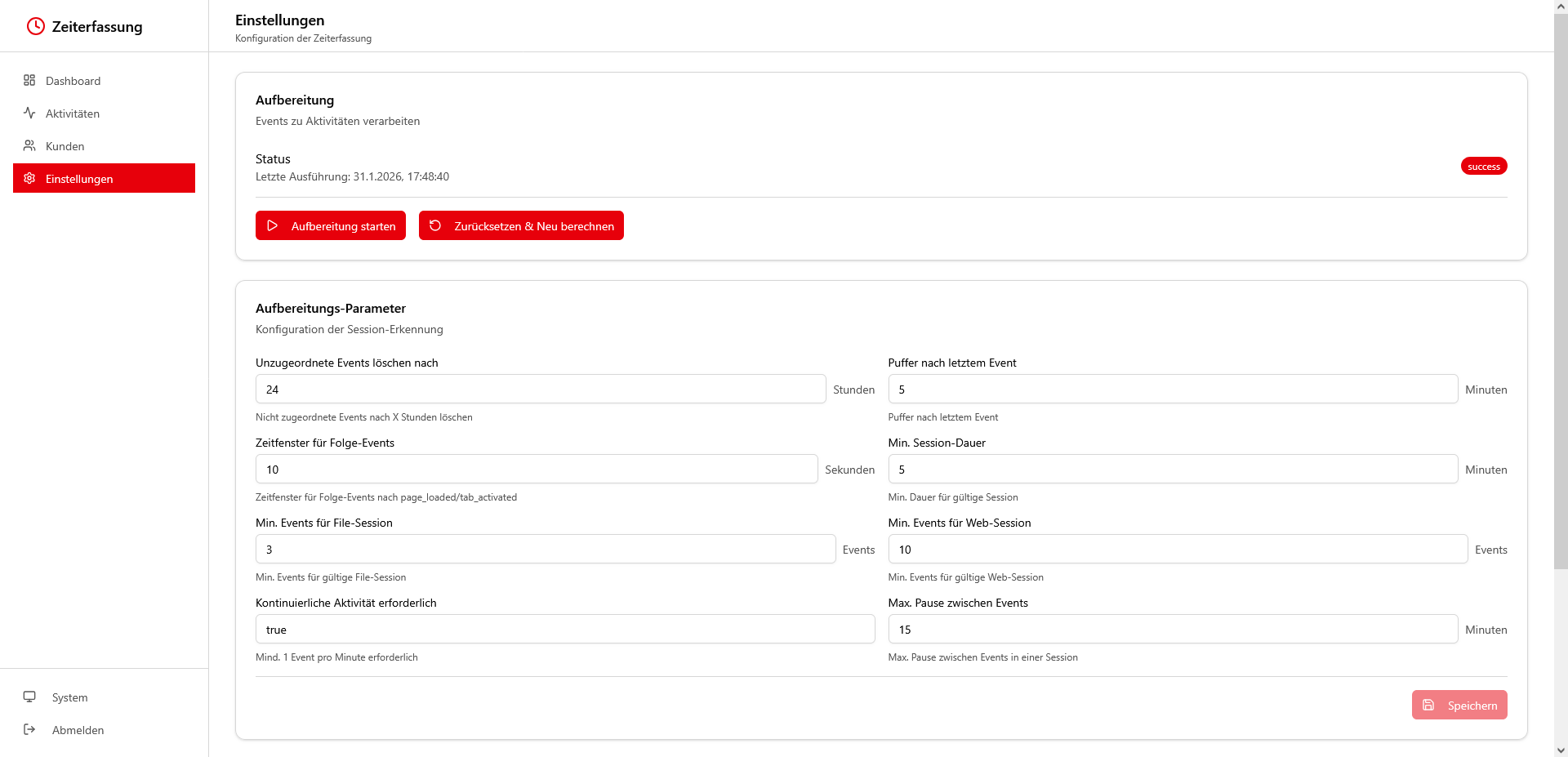
👉 Die Einstellungen steuern die Aufbereitung, zum Beispiel wie lange Inaktivität eine Session beendet oder ab welcher Dauer kurze Unterbrechungen zusammenfallen
👉 Ein Protokoll zeigt, wann die Aufbereitung gelaufen ist, wie viele Events verarbeitet wurden und wie viele Aktivitäten daraus entstanden sind 📊
👉 Login funktioniert per Token, und die API‑URL lässt sich im Frontend setzen, damit lokale Tests oder ein Server‑Setup schnell gewechselt werden
Stack & Tools
Frontend: React mit TypeScript, Vite, TailwindCSS, Radix UI und shadcn/ui für konsistente Oberflächen, Recharts für Diagramme
Backend: Node.js mit Express, APIs mit Swagger/OpenAPI dokumentiert
Daten: MariaDB
Auth: Bearer‑Token, konfigurierbar und für lokale Tests pragmatisch
Deployment/Entwicklung: lokales Setup mit SSH‑Tunnel zur Datenbank, um unabhängig vom Server‑Docker arbeiten zu können
Herausforderungen & Learnings
- Lokale Entwicklung mit Server‑DB: Ein SSH‑Tunnel löste das alte Problem, nicht direkt auf die im Server‑Docker laufende Datenbank zu kommen. Das brachte Geschwindigkeit und weniger Copy/Paste.
- Planung zahlt sich aus: Die ausführliche Struktur aus Woche 1 hat das LLM intelligenter arbeiten lassen. Weniger Rückfragen, weniger Nacharbeiten, schneller lauffähige Teile.
- UI‑System pragmatisch nutzen: shadcn/ui liefert Komponenten als kopierbare Snippets. Ich habe nur die benötigten Bausteine übernommen und gemeinsam mit dem LLM in mein Layout integriert.
- LLM‑Rate‑Limits: So langsam stoße ich hier und da bei Claude an meine Rate-Limits. Da muss ich in Zukunft entsprechend planen oder über ein anderes Abo nachdenken.
Keine Live-Demo
Das Tool läuft vollständig lokal.
Fazit
Woche 23: ✅
ContextTracker macht aus verstreuten Daten des Arbeitstags klare, kundenbezogene Zeiterfassung. In Woche 2 stehen Backend, Datenmodell und ein nutzbares Frontend. Nächster Schritt: die kontinuierliche Datenerfassung via Browser‑Extension und Worker, damit das ganze jetzt auch wirklich echte Daten erfasst. Ich freu mich auf das Ergebnis! 🎯

