
AI Lead Collector: Nie wieder Copy & Paste aus Impressumsseiten!
Bei einem früheren Job im Bereich Kundenakquise habe ich erlebt, wie mühsam Lead-Recherche sein kann. Gekaufte Leads sind oft von zweifelhafter Qualität – und wenn man selbst recherchiert, verbringt man Stunden damit, Adressen aus Impressumsseiten zu kopieren.
Also dachte ich mir: Das muss doch einfacher gehen.
Eine Browser-Extension, die Impressumsdaten automatisch ausliest und in eine Datenbank einträgt.
Meine Anforderungen
Daten mit einem Klick aus einer Impressumsseite ziehen
Korrekturen direkt im Popup-Formular machen
Leads nicht in Excel händisch pflegen, sondern sauber in einer Datenbank speichern
Alles in einer Woche umsetzbar
Mein AI-Workflow
Wie immer habe ich mit AI-Unterstützung gearbeitet – diesmal aber mit einer Besonderheit:
Normalerweise baue ich meine Projekte mit Claude, aber in dieser Woche hatte ich kurzfristig keinen Zugriff und bin stärker auf ChatGPT ausgewichen.
Und das war… sagen wir mal: lehrreich.
ChatGPT hat gerne Features „hinzugefügt“, die ich gar nicht wollte (z. B. automatisch
(at)in E-Mails in ein@verwandeln – und plötzlich tauchten@-Zeichen mitten in Straßennamen auf).Oft hat er mir nicht den kompletten Code gegeben oder nicht alle Dateien gelesen.
Ergebnis: Ich musste das Modell sehr viel enger steuern, damit ich am Ende wirklich den Code bekam, den ich brauchte.
Fazit: Für zukünftige Projekte bleibe ich beim Coden wieder eher bei Claude. ChatGPT hat mir zwar auch geholfen, aber manchmal eher… kreativ als hilfreich. 😅
Was die Extension kann
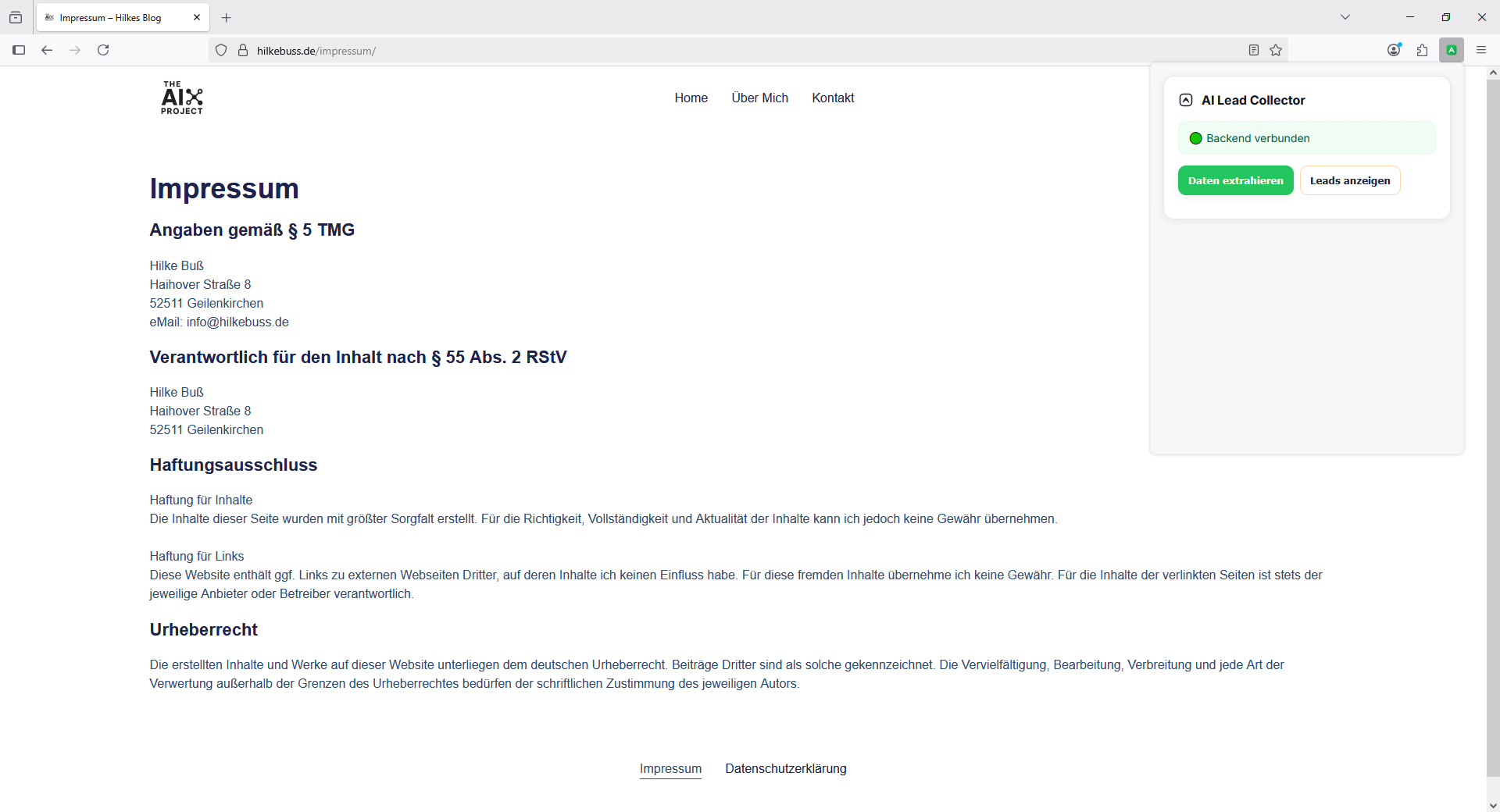
👉 Du gehst auf eine Impressumsseite.
👉 Klick auf „Daten extrahieren“.
👉 Die Extension schickt den Seiteninhalt an mein Backend.
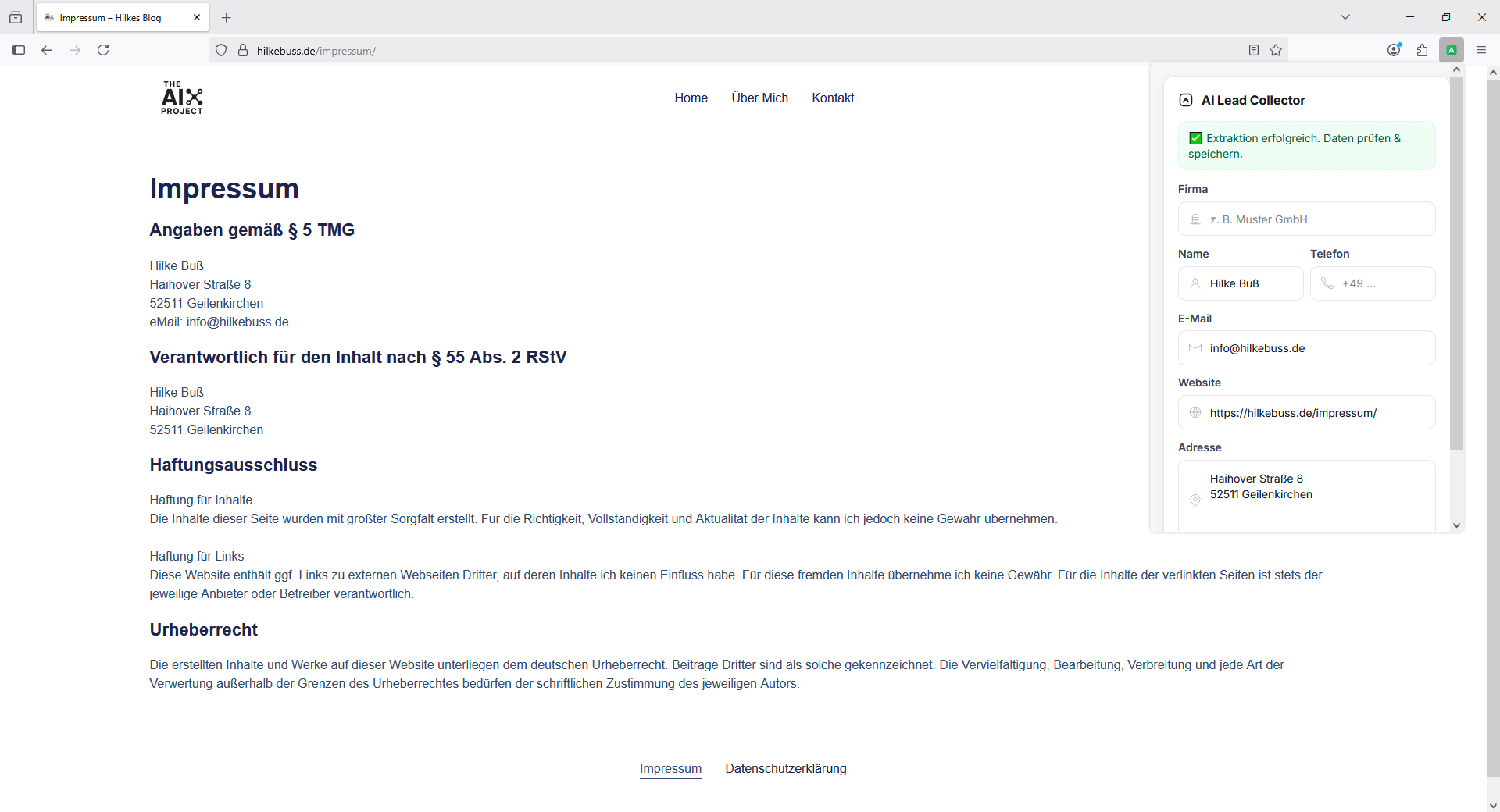
👉 Das Backend extrahiert mit AI die Felder (Firma, Adresse, E-Mail, Telefon).
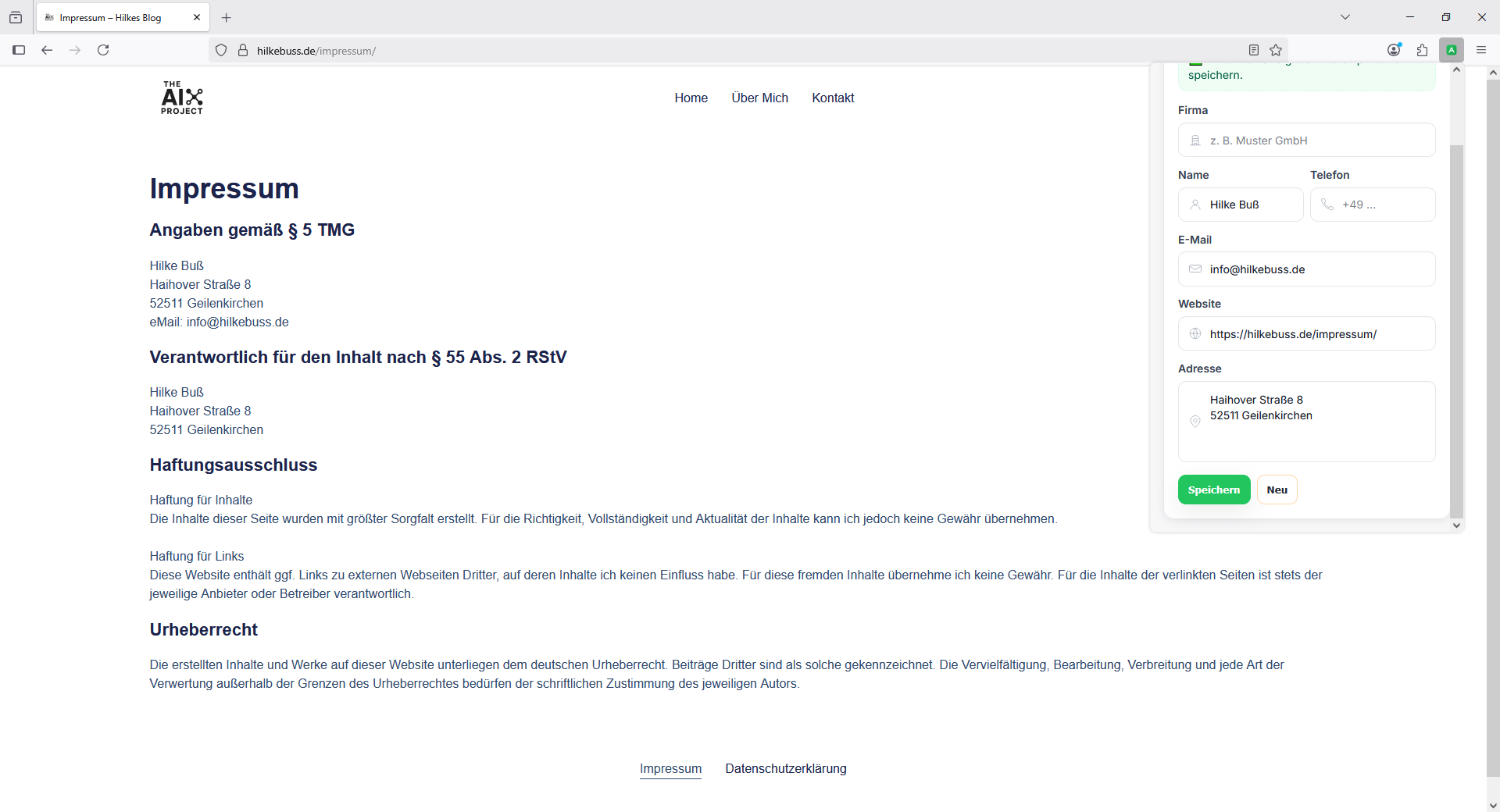
👉 Im Popup kannst du alles prüfen, ggf. korrigieren und speichern.
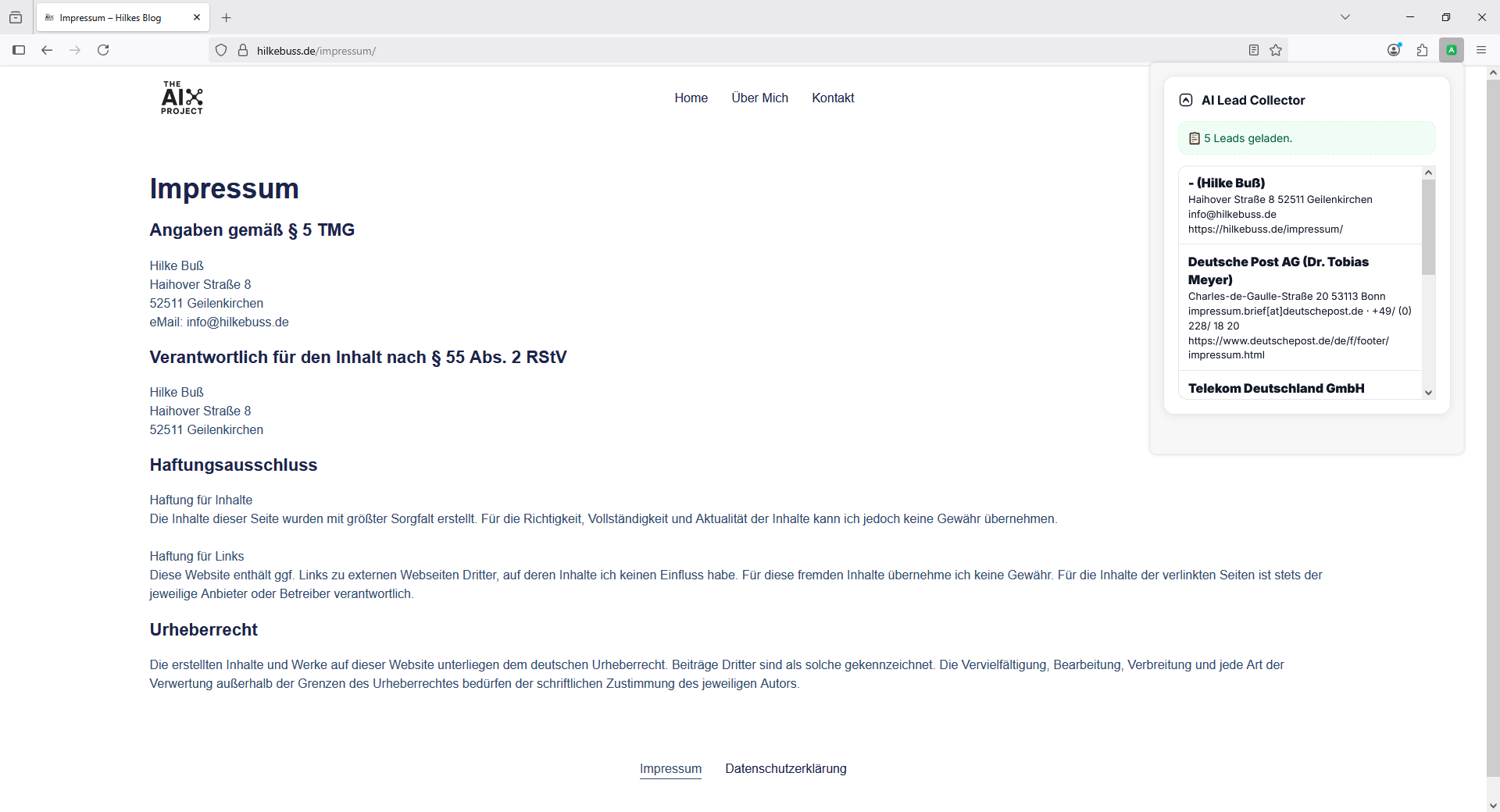
👉 Die Leads landen in einer Datenbank und können wieder angezeigt werden.
Das UI im Popup ist schlicht, aber funktional – Formular, Buttons, eine Leads-Liste. Kein Overkill, sondern auf den Kern fokussiert.
Stack & Tools
Extension: Manifest v2, Content Script, Popup-UI
Backend: Flask + MariaDB, läuft in Docker-Containern
AI: Groq LLM (für die eigentliche Datenextraktion)
Dev: Docker Compose, Claude & ChatGPT (diesmal mehr ChatGPT)
Herausforderungen & Learnings
Docker: Ich habe mich das erste Mal ausgiebiger mit Docker beschäftigt. Anfangs habe ich bei jeder Änderung
docker compose down && upgemacht – bis ich irgendwann herausfand, dass man Container auch automatisch refreshen lassen kann. Das war ein kleiner „Aha!“-Moment.Backend selbst gebaut: Statt n8n diesmal ein eigenes Flask-Backend. Mehr Verantwortung, aber auch viel mehr Kontrolle.
Datenaufbereitung ist entscheidend:
Zeilenumbrüche erhalten, damit PLZ und Hausnummer nicht vermischt werden.
Rohdaten übernehmen, nicht „verschönern“ – sonst hat man zwar hübsche, aber falsche Daten.
Regex-Fallbacks für PLZ/Ort, falls die AI unsicher ist.
AI beim Coding: ChatGPT war manchmal frustrierend. Ich habe viel gelernt über Prompting und Kontrolle – aber nächstes Mal bleibe ich lieber bei Claude.
Keine Live-Demo dieses Mal
Normalerweise erstelle ich für meine Projekte gerne eine kleine Demo-Seite.
Dieses Mal nicht.
Warum?
Die Extension ist mit einem Backend und einer Datenbank verbunden. Das heißt: Im Frontend könnte man die komplette Liste aller gespeicherten Leads sehen. Und wenn mehrere Leute die Extension nutzen würden, wären plötzlich alle Leads für alle sichtbar – datenschutzmäßig ein No-Go.
Das Projekt war zwar als Lernübung gedacht, aber genau solche Überlegungen gehören für mich dazu: Software ist nicht nur ein technisches Experiment, sondern muss auch verantwortungsvoll mit Daten umgehen.
Fazit
Woche 3: ✅
Ich habe gelernt, ein eigenes Backend in Docker aufzusetzen, wie wichtig saubere Datenaufbereitung für AI ist – und dass nicht jedes LLM gleich gut als Coding-Buddy taugt.
Die Extension war ein Lernprojekt, aber theoretisch sofort nutzbar. Der nächste logische Schritt wäre: das Impressum einer beliebigen Website automatisch finden. Klingt einfach, ist es aber nicht – moderne Webseiten verstecken ihre Links gerne in dynamischen Menüs.
Ich freue mich schon auf Woche 4 – mal sehen, welche Idee mir als Nächstes kommt. 😉

